
My Notes on Google's "TrueTime"
AKA, one of the saucy components of Spanner

edit: this blogpost was initially wrong when I published it. Thanks to some comments I got, I learned I didn’t fully understand TrueTime or Spanner — I’ve spent some time learning and understanding the core concept again, and have updated this artifact. This is an externalized resource for me that I hope can be helpful for others.
When I was reading the famous paper on Spanner, Google’s globally distributed linearizable database, I really struggled with the concept of TrueTime, which is a core component of why they were able to get their guarantees. After trying to wrap my head around it, I created the following artifact (IMO, TrueTime deserves a mini-ish paper or post on its own):
So first, let's assume that we have a way to globally agree in a distributed fashion on a single value (this is Paxos, which I won't be going into here). In this case, we want that value that all nodes to agree on to be the correct ordering of transactions. However, even with such a powerful primitive, if we were to just use normal timestamps, we’ll still have issues actually assigning an order to transactions.
Clocks are always inaccurate. Not just a set amount from the current time — they unfortunately also drift. And in different amounts from each other. So in distributed systems, clock synchronization is a hard problem, and generating timestamps that are ordered globally is nontrivial.
Imagine you wanted to globally order transactions by what time they committed. If a clock was off even between two nodes, we already are SOL if we use the local time as the ordering constraint:
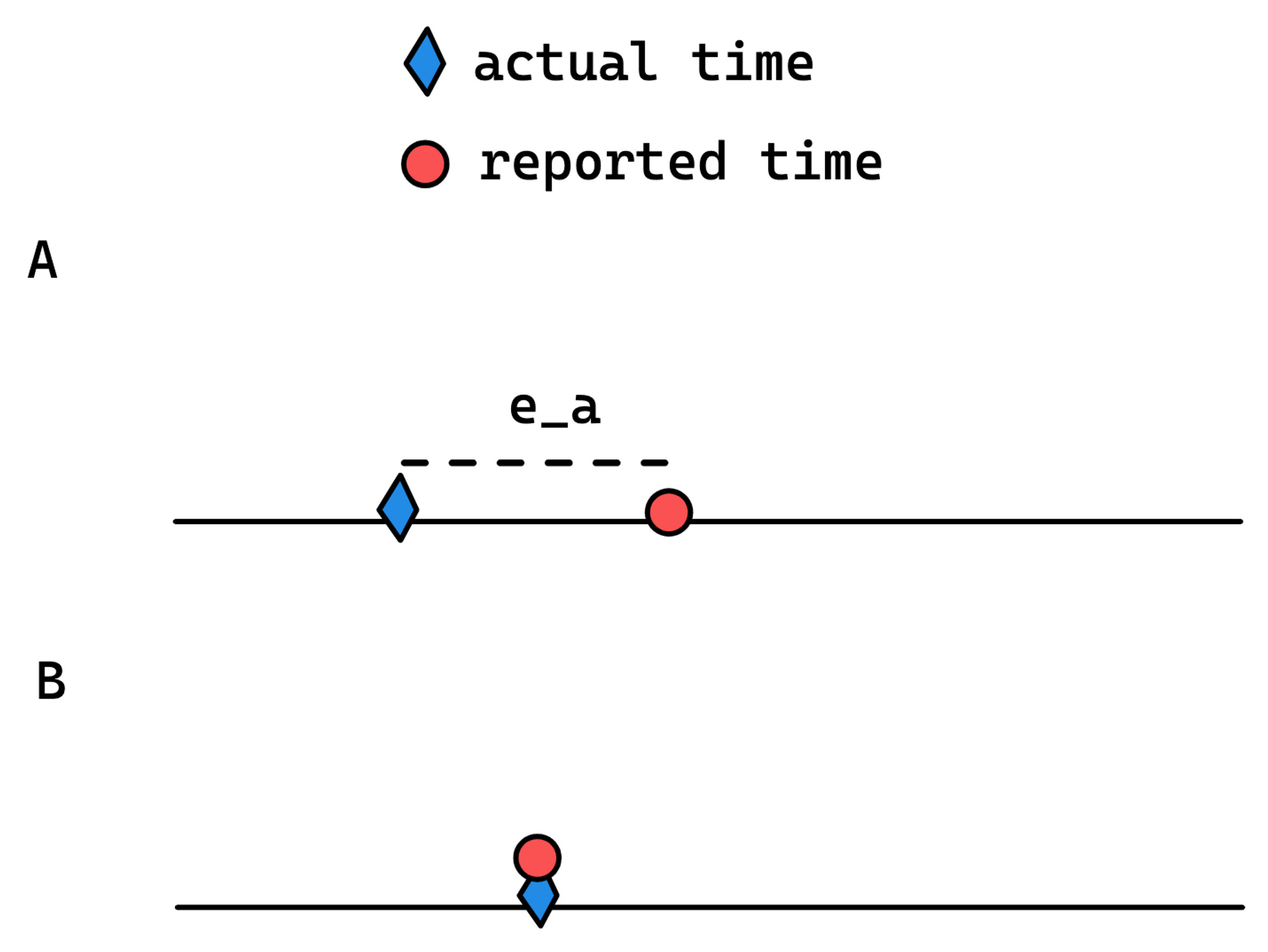
So given nodes A and B with TXNs, and given
where T_A and T_B are transactions on nodes A and B, and the < sign indicates that “transaction A precedes transaction B,” if we were to attempt to globally order the TXNs based on reported timestamp, we’d conclude that T_B < T_A.
This breaks causality (imagine T_B depended on T_A; e.g. T_B was a message reply to T_A). So even if we were to have global agreement on the ordering of transactions, if we use the local timestamps that node A and B generate, the ordering will be incorrect.
Clocks aren’t just slightly inaccurate. They’re like 100s of milliseconds inaccurate, which can lead to large windows where causality will be broken.
So imagine we were able to somehow guarantee that all the clocks are +- 3.5ms of the actual time. So all clocks in the system are 7ms of each other (we’ll call this e. Google actually has this guarantee with the use of GPS + atomic clocks).

Given this, we can actually generate a total ordering even with clocks that are off. First, instead of storing just one number as the timestamp for a transaction, every transaction has a [start, end] bound. end - start = e, and the actual timestamp & the local timestamp are both within the range. Let’s revisit our previous example, but now with time intervals:

So as before, if we were to rely on the “reported time,” we would come to the wrong conclusion that T_B happened before T_A. Here’s a simple fix though now that we have intervals: in the case where we have a conflicting transaction with overlapping intervals, make it so that the one with the later start time waits until it’s no longer overlapping. Concretely, make T_B wait until it’s interval has at least a start of 2. If we were to do this, then there’s no way T_A and T_B can have incorrect ordering.

The key takeaway is that since we have the intervals, we have a bound on how long to wait until there’s no longer a conflict. Before, we couldn’t be sure with just the local timestamps that there was a problem, as we didn’t have a bound on the timestamps’ uncertainty.
Brief thoughts on Spanner
I’ve handwaved some of the finer details on how TrueTime is used in Spanner to keep the scope of this blogpost small. However, technically the scheme I described should be correct to generate a total ordering.
While Google went about creating a globally distributed serializable database like this, there haven’t been many follow-ups that build off of this from my knowledge. This could be for a lot of reasons that I’m definitely not an authority on, but some ideas:
Developers are ok with dealing with eventual consistency
Google’s implementation of Spanner is too expensive
…or the people who want the guarantees are just using the GCP version
The players who deal with scaling problems like this already have their own solutions, public or not.
Regardless, it was fun to learn about this and hopefully this was helpful 🙂
Appendix
Why are the reported times not at the center of the TrueTime intervals?
I’m not entirely sure about this, but (1) the API doesn’t actually specify where the reported time is — just that it’s an interval. I’m guessing it’s possible for the local time to drift within the interval and it depends on factors like network synchronization and the tendency of the local clock to drift.